5 C$ i5 [) Y& s2 _0 e/ G' m9 Q4 ?1. 简介
; q" O" p9 ?, k$ g+ O4 ^& ~. B/ L! h: z1 K& H0 m$ `0 C
目前计算界关注的似乎是多核及并行处理,人们不再谈论如何提高处理器的时钟频率,而是更多地讨论如何在计算机中增加处理器芯核数量。但增加处理器芯核数量能给您带来什么好处,真如广告宣传说的那么神奇吗? `, I# `2 w/ S$ D% y4 {
0 C+ B/ o R: M, w$ H1 C
图 1: Intel Core i7 Processor - PowerMill 10 benchmarks测试中使用的多核处理器之一。
PowerMILL 10 以以下两种独特的方式来应用并行计算技术:
; ^! b9 s$ m) M" |5 n
' I. ~: b$ T% S O% s6 ^8 Y $ L! O8 j& @4 h! s7 X @- `/ e
首先,在前台准备、计算或编辑刀具路径的同时,在后台计算其它刀具路径,而处理速度几乎不受影响,使生产力成倍增长。这就是Delcam的后台处理,它适用于任何硬件,而多核计算机的效果更显著。
3 Y4 j/ b& P4 z4 h. M c* Q Y7 n, Z" K. w1 ], S
其次,并行处理将复杂计算分割成多个独立部分而同时对各个部分进行计算,也即单个计算会在全部CPU芯片中同时进行,从而缩短计算时间。并行处理必须在多核计算机上进行。
; h+ a. D6 g" W2 R" X6 }1 t& F% u2 o7 i& p6 L/ b8 [
再者,也就是 PowerMILL 10所独有的在前台和后台同步进行并行处理, 这无疑使 PowerMILL 10 的性能较前面任何一个 PowerMILL 版本都有质的飞跃。
4 W' x9 G9 D7 u; F5 G& u f# {; X" s* d
图 2: PowerMILL 10 在4核计算机上前台和后台同步进行并行处理计算图示。
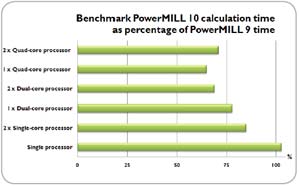
4 |# K# e( m8 E* M R( aDelcam对多个刀具路径策略计算测试表明,和早期单核计算机计算相比,使用多核计算机计算,刀具路径计算速度可提高3-4倍。实际的效果和硬件配置和所计算的刀具路径策略密切相关,随后我们将讨论此问题。
1 v' r- u+ |: y
" y1 E8 ~9 v2 D4 X, J# mPowerMILL 10 优点:
6 R8 Z+ k1 i" v5 {, C! n: {/ I! ^( Y+ _( e* N e* d0 j
● 平行刀具路径计算速度快4倍8 H4 M$ Z( g0 n. l$ I/ }0 Q
● 最多可节省编程时间 2.5 倍*! |) t! `; r; x
● 减少刀具路径计算等待时间3 W4 N, v9 Z+ `. E* [8 t+ _
● 增加额外工作能力( i# r& m5 _! _4 Q2 e; v C
● 显著提高加工制造生产力
& J4 p! N M6 c; d* A● 缩短交货时间
& t& j& z- P+ p9 }0 S● 可处理内存占用更大的模型文件
0 Z( Y: h# d. H2 N- i$ D4 N*Delcam对多个刀具路径计算测试结果。 (见第3页PowerMILL 10性能改善中的第3部分。)* X- R; Q) B' J( U1 H |, D& ]
) U. H& V- T3 n, m o% i3 h
8 c) B6 m. X5 f% g7 S; A: w
1.1. 预期效益怎样?1 p3 {& |. c: S. t& B' o
, g! k/ K- h9 t4 G* n/ Q0 G" ~
我们来看一个简单的例子。假设每天工作8小时,而其中50%的时间用于刀具路径计算,那么一年就相当于有大约120个工作日在不断地进行刀具路径计算。7 u6 `$ ]2 D' N( j: b! F
' K4 e8 C5 e7 e" B7 \( E
对一系列刀具路径计算测试结果表明,在一4核计算机上使用PowerMILL 10进行计算,刀具路径计算时间可节省 60% ,也就是说每年可只用不到50天来计算刀具路径。, B) T( O9 ?3 o& w
. D3 \7 a4 x4 t0 K+ L! e; d2 m7 M图 3: 在多核计算机上使用PowerMILL 10计算可能的时间节省 (天)。 . I- s; k' b8 ]- Y$ w* P/ V& D
以美元计算,如果产生刀具路径的内部成本是每小时50美元(考虑到运营商的成本,停机时间与等待数据造成的加工延误),这将相当于节省了70天的刀具路径计算费用,或是每年可节省的费用超过28,000.00美圆。
3 A( X; \0 d9 @, T/ C
8 H# N: H, B' l9 R$ T 5 _/ S9 F# C- }4 ]0 h. e 5 _/ S9 F# C- }4 ]0 h. e
PowerMILL在多核处理器计算机上使用运行的潜在经济效益
- q$ J8 l2 L3 x5 `' U$ W1.2. 预期效益可实现吗?
' b' o4 F' D* O) e' u" X. k4 }4 g8 t% D2 t
尽管某些媒体所宣传的所谓并行处理可提高效益3-4倍是不现实的,但并行处理可以极大缩短计算时间则是不容置疑的。由于可在前台策划、产生和编辑刀具路径,而在后台计算刀具路径,因此可显著提高生产力。当交货时间紧迫时,这无疑可提升您的竞争力。
/ F) U% H* t3 T6 q* F4 x: K4 x
3 C; n" l6 v7 I" G1 L6 C k& ^% r) s* j" k
2. PowerMILL 10 中生产力的提升
+ L6 g4 l+ w* a2 s# g4 P4 M
; V' a$ V" v7 k# k6 ]) P. G/ q& c* jPowerMILL 10 的许多功能完善都体现在缩短计算时间或尽量利用系统闲置时间计算上,它们极大地提高了产品的生产力。
2 f( T, X8 {% f2 ^. l3 s8 i2 Q8 _% s! L
后台处理 - 在前台和PowerMILL 交互的同时,于后台计算刀具路径、边界或单独残留模型状态。$ b- @. \9 B) }1 r: u
" x3 h0 U A( |# r并行处理 - 将全部计算分割成若干个子任务并同步处理,可极大缩短计算时间。并行处理仅适用于多核处理器。
" y: V' M8 ^* R5 ~7 ~
) u8 u7 G4 t t+ L! M1 D9 i+ p) X$ t- |加速特殊刀具路径计算 - 区域清除刀具路径计算时占用更小的内存,计算时间更短。这对路径计算中通常出现内存溢出的大型模型尤其重要。5 A H0 {3 N( f' v& I0 h
) t. U. q, M3 F1 P" f" [# \
2.1. 后台处理
3 E% q; k0 m6 }$ K( ^. x8 W2 ^: o4 l4 a2 s8 \
PowerMILL 10 允许在对某些计算(例如生成刀具路径和边界)进行后台操作的同时,在前台做策略准备、编辑甚至计算其它刀具路径。
9 c1 W% J i/ z
; [( a3 E- D1 U S* A; O( f6 U图 5: PowerMILL 10后台处理时间比较。前台准备、编辑或计算刀具路径的同时,在后台计算刀具路径。8 F% t; [5 s& E. \1 T
% N+ i3 G# d. ]4 m( z) l' n4 I/ |
后台处理使用十分简便,只需在刀具路径对话视窗中点击新添的‘队列’按钮,而不是点击‘计算’按钮,PowerMILL 即自动检查有关设置(如毛坯、刀具...)是否设置无误,随后即将刀具路径置于后台计算队列。您可继续您的工作,而 PowerMILL 按队列次序在后台逐个计算刀具路径。
$ L1 X! N# A* q- @4 P* q* ?7 n3 ^3 v/ Z$ T9 _! R7 _
注: 除刀具路径外,后台处理也适用于边界和残留模型计算。! K5 o4 R% N7 B- Y
% e! E2 Q4 P9 u; K9 v
2.2. 并行处理
, P0 ~5 c. M) H& n. {* [0 W: e/ u. o4 C! `) k; a4 g2 G! Q6 i* F
PowerMILL 10 最重要但最不容易看到的功能提高是在刀具路径计算中使用了并行处理技术。
- a2 |7 L( p: \/ n& j/ H! t在 PowerMILL 9 中,为改善点分别计算,计算中使用了很多并行处理方法,而在. N" z+ n& [1 Q+ |. Q D7 }
PowerMILL 10 中,刀具在模型上的运动的计算代码,也使用并行处理方法,为此,平行加工计算几乎全部都以并行处理方式进行。2 {# j& V8 E# N; `0 C
9 \1 A' F0 ~! n- L图 6: 在全部4核上做多线程平行刀具路径处理 * X6 I- T" {5 y( P1 S2 d
使用此代码的其它策略包括:, ?- W6 k/ U5 R2 \0 w2 l
* w' j2 ~% L$ W" H5 Z
|

 |关于我们|sitemap|小黑屋|Archiver|手机版|UG网-UG技术论坛-青华数控模具培训学校
( 粤ICP备15108561号 )
|关于我们|sitemap|小黑屋|Archiver|手机版|UG网-UG技术论坛-青华数控模具培训学校
( 粤ICP备15108561号 )


 狗仔卡
狗仔卡 发表于 2009-8-16 08:49
发表于 2009-8-16 08:49







 提升卡
提升卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡